In her excellent blog post entitled “Batch Mode Hacks for Rowstore Queries in SQL Server“, Kendra Little b|t pays homage to Itzik Ben-Gan, Niko Neugebauer, and others.
The solutions she details will indeed result in batch mode for rowstore queries. I had already seen the solution proposed by Mr. Ben-Gan, and as is typically the case, a simple example is given to illustrate the concept, and these types of examples are almost always single-threaded.
I have a client that used Itzik Ben-Gan’s solution of creating a filtered nonclustered columnstore index to achieve batch mode on a rowstore (in fact I proposed that the client consider it). They have an OLTP system, and often perform YTD calculations. When they tested, processing time was reduced by 30 to 50 percent, without touching a single line of application code. If that ain’t low hanging fruit, I don’t know what is —
However, during testing, I noticed some intermittent blocking that didn’t make sense to me. But I couldn’t nail it down, and they went live with the “filtered nonclustered columnstore index” solution.
Once they deployed – and there was a lot of concurrency – I could see what had eluded me during my proof of concept: blocking in tempdb.
The repro is super-simple:
- Create a table, and insert some sample data
- Create a stored procedure that does the following:
SELECT from that table into a #temp table
Create a filtered nonclustered columnstore index on the #temp table, using a filter that cannot possibly be true, i.e. IDcolumn < 0 and IDcolumn > 0
SELECT from the #temp table (return results)
From the first connection, issue a BEGIN TRAN execute the stored procedure. Note the spid for this connection. Then open a separate connection, issue a BEGIN TRAN and execute the stored procedure. Note the spid for this connection.
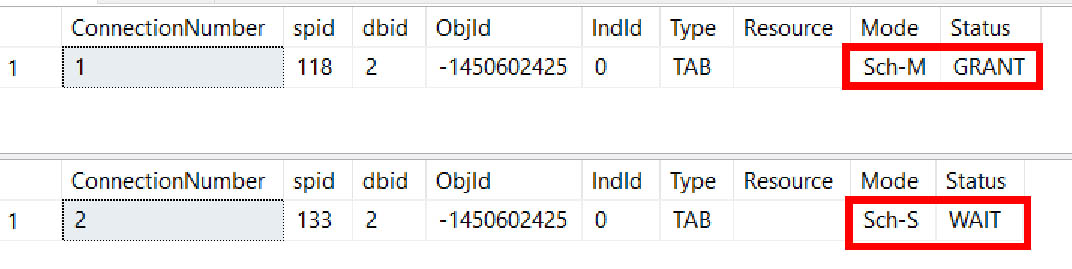
You’ll notice that the first connection has no issues, but when you execute the proc in the second connection, it gets blocked.
When you peel back the layers, you can see that the first connection requests and obtains a schema modification lock on the #temp table (Sch-M).
The second connection requests a schema stability lock on the same object_id, and is blocked (Sch-S).
To be clear, what’s happening here is that separate connections are placing incompatible locks on the same temporary object in tempdb, which is supposed to be impossible (but in fact the object_id is the same). My gut tells me that this is perhaps related to metadata when creating the NCCI, but I couldn’t prove that.
It should be noted that if you remove the filter on the NCCI, there is no blocking, and also if you use a regular filtered nonclustered index (not columnstore), this issue persists. Of course, in the real world, removing the filter is not an option because what we’re interested in speed, and if there’s one thing that columnstore indexes are not fast at, it’s being created.
Hopefully if/when Microsoft fixes this, it will be back ported to earlier versions of SQL Server.
I can reproduce this on SQL 2016 and 2017 (and even 2019, but that’s not really fair, cause it’s not RTM yet…)
If you think that Microsoft should fix this, please upvote my Azure User Voice entry here.
Repro code:
/*
Ned Otter
Repro for incompatible lock types when two connections both call the same procedure,
and a filtered nonclustered columnstore index is created on a #temp table (for batch mode).
If you remove the filter from the NCCI, there is no blocking, but also if you use a regular filtered nonclustered index (not columnstore), this issue persists.
Version tested against:
SQL 2016/SP2/CU2
SQL 2017 RTM CU5
SQL 2019 CTP2.1
*/
/*
##################################
Setup: Create table and insert rows
##################################
*/
DROP TABLE IF EXISTS dbo.SourceTable
GO
CREATE TABLE dbo.SourceTable
(
col1 INT NOT NULL
,col2 INT NOT NULL
,col3 DATETIME
)
INSERT dbo.SourceTable
(
col1
,col2
,col3
)
VALUES
( 12345
,6789
,'2018-09-01 00:00:00.000'
)
GO
/*
##################################
Setup: Create procedure
##################################
*/
CREATE OR ALTER PROCEDURE [dbo].[Proc_GetRows]
AS
SELECT *
INTO #TempTable
FROM dbo.SourceTable
CREATE NONCLUSTERED COLUMNSTORE INDEX NCCI_#TempTable ON #TempTable(col1)
WHERE (col1 < 0 AND col1 > 0)
SELECT col1
,col2
,col3
FROM #TempTable
GO
/*
##################################
Execute the following statements in two separate connections
##################################
*/
SELECT @@SPID
GO
SET XACT_ABORT ON
SET NOCOUNT ON
BEGIN TRANSACTION
EXEC [dbo].[Proc_GetRows]
--ROLLBACK
/*
##################################
Verify locking/blocking
##################################
*/
DROP TABLE IF EXISTS #locks
GO
CREATE TABLE #locks
(
spid smallint
,dbid smallint
,ObjId int
,IndId smallint
,Type nchar(4)
,Resource nchar(32)
,Mode nvarchar(8)
,Status nvarchar(5)
)
INSERT #locks
EXEC sp_lock
SELECT DISTINCT
'1' AS ConnectionNumber
,*
FROM #locks
WHERE spid = <SPID_from_Connection1>
AND Type = 'TAB'
AND ObjId < 0
SELECT DISTINCT
'2' AS ConnectionNumber
,*
FROM #locks
WHERE spid = <SPID_from_Connection2>
AND Type = 'TAB'
AND ObjId < 0
DECLARE @TableID INT =
(
SELECT DISTINCT ObjId
FROM #locks
WHERE spid = <SPID_from_Connection1>
AND dbid = 2
AND Type = 'TAB'
AND ObjId < 0
)
Pingback: Tempdb Blocking With Non-Clustered Columnstore Indexes – Curated SQL